Main Abstractions
This is the conceptual map of MicroRaft. Read it before the tutorial if you want the names, responsibilities, and extension points to make sense while you wire your own service.
RaftNode as the core runtime, then StateMachine, Transport, and RaftStore as your boundaries.
How to read this page
RaftNodeis the core runtime object you embedStateMachine,Transport, andRaftStoreare the boundaries you implement around itRaftConfigcontrols protocol-level behavior and operational tradeoffs
RaftConfig
RaftConfig
contains configuration options related to the
Raft consensus algorithm and MicroRaft's implementation. Please check the
Configuration section for details.
What this section clarifies
RaftConfig is where protocol behavior becomes an operational tradeoff. This is the abstraction to revisit when you need to tune latency, elections, batching, or snapshots.
RaftNode
RaftNode
runs the Raft consensus algorithm as a member of
a Raft group. A Raft group is a cluster of RaftNode instances that behave as a
replicated state machine. RaftNode contains APIs for replicating operations,
performing queries, applying membership changes in the Raft group, handling Raft
RPCs and responses, etc.
Raft nodes are identified by [group id, node id] pairs. Multiple Raft groups
can run in the same environment, distributed or even in a single JVM process,
and they can be discriminated from each other with unique group ids. A single
JVM process can run multiple Raft nodes that belong to different Raft groups or
even the same Raft group.
RaftNodes execute the Raft consensus algorithm with the
Actor model. In this model, each
RaftNode runs in a single-threaded manner. It
uses a RaftNodeExecutor to sequentially handle API calls and RaftMessage
objects sent by other RaftNodes. The communication between RaftNodes are
implemented with the message-passing approach and abstracted away with the
Transport interface.
In addition to these interfaces that abstract away task execution and
networking, RaftNodes use StateMachine objects to execute queries and
committed operations, and RaftStore objects to persist internal Raft state to
stable storage to be able to recover from crashes.
All of these abstractions are explained below.
What this section clarifies
RaftNode is the center of the system. It owns protocol execution, but depends on your service boundaries for persistence, transport, and state machine behavior.
Runtime concepts
RaftNodeis the core runtime you embedRaftRoleandRaftNodeStatusdescribe cluster behavior over time
Integration boundaries
Transportcovers networkingStateMachinecovers deterministic business logicRaftStorecovers durability and recovery
Protocol surfaces
RaftConfigtunes timing and replicationRaftModelandRaftModelFactorydefine on-wire and on-disk objects
Use this page for
- learning the vocabulary before the tutorial
- finding the right extension point for your integration
- understanding what MicroRaft does not implement for you
RaftEndpoint
RaftEndpoint
represents an endpoint that participates to
at least one Raft group and executes the Raft consensus algorithm with a
RaftNode.
RaftNode differentiates members of a Raft group with a unique id. MicroRaft
users need to provide a unique id for each RaftEndpoint. Other than this
information, RaftEndpoint implementations can contain custom fields, such as
network addresses and tags, to be utilized by Transport implementations.
What this section clarifies
RaftEndpoint is identity, not business logic. Keep it stable and serializable enough for your transport and discovery story.
RaftRole
RaftRole
denotes the roles of RaftNodes as specified in
the Raft consensus algorithm. Currently, MicroRaft implements the main roles
defined in the paper: LEADER, CANDIDATE, and FOLLOWER. Moreover, it also
implements an extension adding non-voting members: LEARNER. The WITNESS role
is not implemented yet, but it's on the roadmap.
What this section clarifies
RaftRole tells you how a node participates in protocol progress. It is the right lens for understanding elections, replication authority, and learner behavior.
RaftNodeStatus
RaftNodeStatus
denotes the statuses of a RaftNode during
its own and its Raft group's lifecycle. A RaftNode is in the INITIAL status
when it is created, and moves to the ACTIVE status when it is started with a
RaftNode.start() call. It stays in this status until either a membership
change is triggered in the Raft group, or either the Raft group or Raft node is
terminated.
What this section clarifies
RaftNodeStatus is broader than role. It helps you reason about lifecycle transitions such as startup, active service, termination, and membership-driven changes.
StateMachine
StateMachine
enables users to implement arbitrary
services, such as an atomic register or a key-value store, and execute
operations on them. Currently, MicroRaft supports memory-based state machines
with datasets in the gigabytes.
RaftNode does not deal with the actual logic of committed operations. Once a
given operation is committed with the Raft consensus algorithm, i.e., it is
replicated to the majority of the Raft group, the operation is passed to the
provided StateMachine implementation. It is the StateMachine
implementation's responsibility to ensure deterministic execution of committed
operations.
Since RaftNodeExecutor ensures the thread-safe execution of the tasks
submitted by RaftNodes, which include actual execution of committed
user-supplied operations, StateMachine implementations do not need to be
thread-safe.
What this section clarifies
StateMachine is where your product logic lives. The key contract is deterministic execution, not framework integration convenience.
RaftModel and RaftModelFactory
RaftModel
is the base interface for the objects that hit network and disk. There are 2
other interfaces extending this interface:
BaseLogEntry
and
RaftMessage.
BaseLogEntry is used for representing log
and snapshot entries stored in the Raft log. RaftMessage is used for Raft RPCs
and their responses. Please see the interfaces inside
io.microraft.model
for more details. In addition, there is a
RaftModelFactory
interface for creating RaftModel
objects with the builder pattern.
MicroRaft comes with a default POJO-style implementation of these interfaces
available under the
io.microraft.model.impl
package. Users of MicroRaft can define serialization & deserialization
strategies for the default implementation objects, or implement the
RaftModel interfaces with a serialization framework, such as
Protocol Buffers.
What this section clarifies
RaftModel and RaftModelFactory define the objects that cross network and storage boundaries. Reach for them when the default POJO model is not enough for your serialization stack.
Transport
Transport
is used for communicating Raft nodes with each other.
Transport
implementations must be able to serialize
RaftMessage
objects created by
RaftModelFactory.
MicroRaft requires a minimum set of
functionality for networking. There are only two methods in this interface, one
for sending a
RaftMessage
to a
RaftEndpoint
and another one for checking reachability of a
RaftEndpoint.
What this section clarifies
Transport is intentionally narrow. MicroRaft expects you to bring the networking system, but it keeps the required contract small.
RaftStore and RestoredRaftState
RaftStore
is used for persisting the internal state of the
Raft consensus algorithm. Its implementations must provide the durability
guarantees defined in the interface.
If a RaftNode crashes, its persisted state could be read back from stable
storage into a
RestoredRaftState
object and the RaftNode could be
restored back. RestoredRaftState contains all the necessary information to
recover RaftNode instances from crashes.
Important
RaftStore does not persist internal state of StateMachine implementations. Upon recovery, a RaftNode starts with an empty state machine, discovers the current commit index, and re-executes Raft log entries to rebuild state.
What this section clarifies
RaftStore covers protocol durability, not full application recovery. Your service still owns the broader persistence and replay story.
RaftNodeExecutor
RaftNodeExecutor
is used by
RaftNode
to execute the Raft consensus algorithm with the
Actor model.
A
RaftNode
runs by submitting tasks to its
RaftNodeExecutor.
All tasks submitted by a
RaftNode
must be executed serially, with maintaining the
happens-before relationship,
so that the Raft consensus
algorithm and the user-provided state machine logic could be executed without
synchronization.
MicroRaft contains a default implementation,
DefaultRaftNodeExecutor.
It internally uses a
single-threaded ScheduledExecutorService and should be suitable for most of
the use-cases. Users of MicroRaft can provide their own
RaftNodeExecutor
implementations if they want to run
RaftNodes
in their own threading system according to the
rules defined by MicroRaft.
What this section clarifies
RaftNodeExecutor is the concurrency boundary. Change it only if you need MicroRaft to live inside an existing execution model you already trust.
RaftException
RaftException
is the base class for Raft-related exceptions. MicroRaft defines a number of
custom exceptions
to report some certain failure scenarios
to clients.
Running a Group
How to run a Raft group
Always required
- endpoint identity
- state machine implementation
- transport implementation
Optional but common
- custom model serialization
- durable
RaftStore - custom executor integration
In order to run a Raft group (i.e., Raft cluster) using MicroRaft, we need to:
-
implement the
RaftEndpointinterface to identifyRaftNodes we are going to run, -
provide a
StateMachineimplementation for the actual state machine logic (key-value store, atomic register, etc.), -
(optional) implement the
RaftModelandRaftModelFactoryinterfaces to create Raft RPC request / response objects and Raft log entries, or simply use the default POJO-style implementation of these interfaces available under theio.microraft.model.implpackage, -
provide a
Transportimplementation to realize serialization ofRaftModelobjects and networking, -
(optional) provide a
RaftStoreimplementation if we want to restore crashed Raft nodes. We can persist the internal Raft node state to stable storage via theRaftStoreinterface and recover from Raft node crashes by restoring persisted Raft state. Otherwise, we could use the already-existingNopRaftStoreutility which makes the internal Raft state volatile and disables crash-recovery. If we don't implement persistence, crashed Raft nodes cannot be restarted and need to be removed from the Raft group to not to damage availability. Note that the lack of persistence limits the overall fault tolerance capabilities of Raft groups. Please refer to the Resiliency and Fault Tolerance section to learn more about MicroRaft's fault tolerance capabilities. -
build a discovery and RPC mechanism to replicate and commit operations on a Raft group. This is required because simplicity is the primary concern for MicroRaft's design philosophy. MicroRaft offers a minimum API set to cover the fundamental functionality and enables its users to implement higher-level abstractions, such as an RPC system with request routing, retries, and deduplication. For instance, MicroRaft neither broadcasts the Raft group members to any external discovery system, nor integrates with any observability tool, but it exposes all necessary information, such as Raft group members, leader Raft endpoint, term, commit index, via
RaftNodeReport, which can be accessed viaRaftNode.getReport()andRaftNodeReportListener. We can use that information to feed our discovery services and monitoring tools. Similarly, the public APIs onRaftNodedo not employ request routing or retry mechanisms. For instance, if a client tries to replicate an operation via a follower or a candidateRaftNode,RaftNoderesponds back with aNotLeaderException, instead of internally forwarding the operation to the leaderRaftNode.NotLeaderExceptioncontainsRaftEndpointof the current leaderRaftNodeso that clients can send their requests to it.
Design boundary
MicroRaft gives you the consensus core. Discovery, request routing, retries, and observability wiring still belong to the service you build around it.
In the next section, we will build an atomic register on top of MicroRaft to demonstrate how to implement and use MicroRaft's main abstractions.
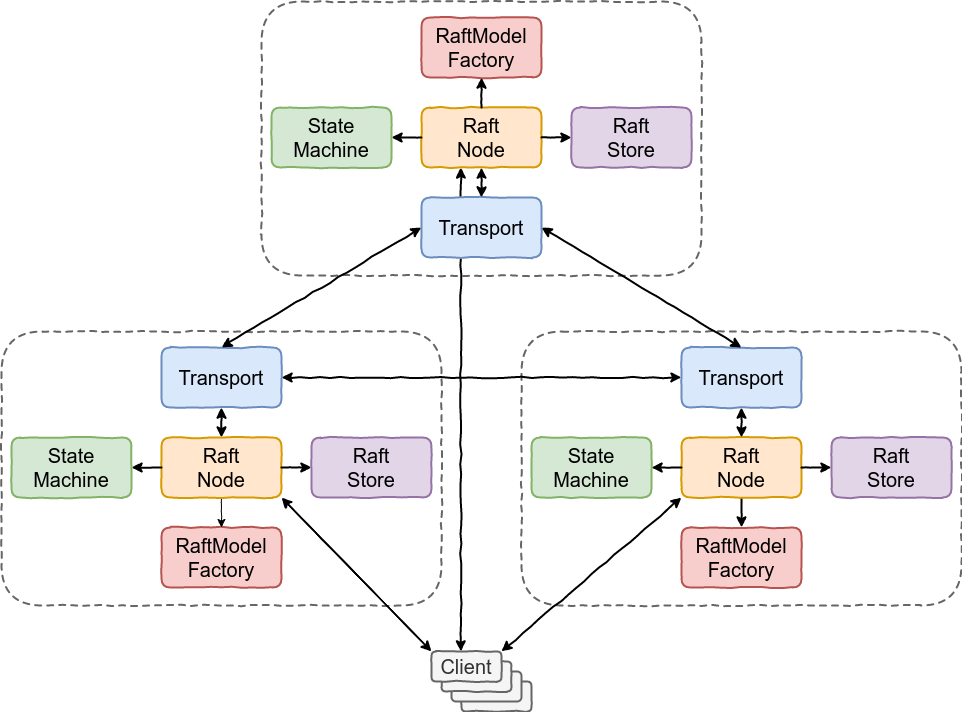
Architecture
Architectural overview of a Raft group
The following figure depicts an architectural overview of a Raft group based on
the main abstractions explained above. Clients talk to the leader RaftNode for
replicating operations. They can talk to both the leader and follower
RaftNodes for running queries with different consistency guarantees.
RaftNode uses RaftModelFactory to create Raft log entries, snapshot entries,
and Raft RPC request and response objects. Each RaftNode uses its Transport
object to communicate with the other RaftNodes. It also uses RaftStore to
persist Raft log entries and snapshots to stable storage. Last, once a log entry
is committed, i.e, it is successfully replicated to the majority of the Raft
group, its operation is passed to StateMachine for execution, and output of
the execution is returned to the client by the leader RaftNode.
Next Up
What is next?
In the next section, we will build an atomic register on top of MicroRaft.