Today a Raft follower, tomorrow a Raft leader
A Java Raft leader-election deep dive on failure detection, election timing, quorum loss, and the availability impact of timeout design.
At a glance
- Why MicroRaft separates detection timeout from retry timeout
- How disruptive followers are prevented from hurting availability
- Why leaders step down when quorum is gone
Readers are expected to have an understanding of how leader election works in Raft. Raft paper already does a great job on explaining its details and safety properties. In addition, there is a number of visual demonstrations and blog posts available on the web, for example The Secret Lives of Data.
In this blog post, we follow
the terminology used in MicroRaft. In summary, a Raft node runs the Raft
consensus algorithm as a member of a Raft group. A Raft group is a cluster of
Raft nodes that behave as a replicated state machine.
RaftNode
interface contains APIs for handling client
requests, Raft RPCs, etc.
"Today a reader, tomorrow a leader." -- Margaret Fuller
Raft is a leader-based consensus algorithm. It solves the consensus problem in the context of replicated state machines. It starts with electing a leader among servers. A new leader is elected if the current leader fails. The leader becomes responsible for managing a replicated log. Clients send their operations, requests in other words, to the leader. Upon receiving an operation, the leader first ensures that the operation is appended to the local logs of sufficient number (i.e., more than half) of servers, then commits the operation. Raft guarantees that each server ends up with the same final state by committing and executing the same set of operations in the same order.
Since availability of a Raft cluster relies on having a functional leader, graceful handling of leader failures becomes very important for robustness of a Raft implementation.
This post is about availability under leader instability. The main ideas are timeout separation, disruptive follower control, and leader self-demotion on quorum loss.
Separating the leader failure detection and election timeouts
MicroRaft splits “detect failure” from “retry election”. That reduces unnecessary elections without making split-vote recovery painfully slow.
Raft's leader election logic runs in 2 steps. First, Raft nodes decide that there is no live leader in the Raft cluster. A leader Raft node sends periodic heartbeats to its followers to denote its liveliness. If a follower does not hear from the leader for some time, it assumes that the leader has crashed. The second step starts here to elect a new leader. The follower moves to the next term with the candidate role, votes for itself, and asks votes from the other servers in the Raft cluster. If it cannot collect the majority votes or hears from a new leader for some time, it starts a new leader election round for the next term. This situation is called split vote.
Raft uses a single timeout value for both of these steps: election timeout. In order to prevent split vote situations, a bit of randomness is added to election timeouts so that followers do not switch to the candidate role at the same time, hence they can vote for each other. The Raft paper states that an election timeout around half a second would be generally sufficient to prevent unnecessary leader elections and split vote situations.
Our experience is a short election timeout value works fine for electing a new leader promptly after an actual leader failure. However, it could also cause unnecessary leader elections. A leader Raft node could fail to send heartbeats on time because of a GC pause or a long-running user operation occupying the Raft thread. Its CPU and network resources could be also congested by other Raft nodes belonging to different Raft groups in a Multi Raft deployment. In such cases, followers may decide to start a new leader election round while the leader is actually alive. Even if electing a new leader does not hurt correctness, it may not necessarily improve availability. A Raft group does not handle new requests during leader elections, and it usually takes some time for clients to discover the new leader. If the previous leader was slowed down by a long-running operation, retrying the operation on the new leader could make more harm on availability. To eliminate unnecessary leader elections, we can simply use a larger election timeout, but then leader elections can get delayed in case of split vote, even if it is a low probability. For instance, if election timeout is 10 seconds, it takes 10 seconds to trigger leader election, and if it ends up with split vote, it takes more than 20 seconds to elect a new leader.
MicroRaft chooses a more verbose approach and uses 2 timeout values for leader election: leader heartbeat timeout and leader election timeout. Leader heartbeat timeout is the duration for a follower to detect failure of the current leader and trigger leader election. Leader election timeout is the duration candidates wait before giving up a leader election round and move to the next term for a new round. These 2 timeout values allow the 2 steps of Raft's leader election logic to be tuned separately. Their default values are 10 seconds and 1 second respectively. When a leader crashes, it takes 10 seconds to trigger leader election. If the split vote situation occurs, a new leader election round starts after just 1 second, and the leader election logic completes after 11-12 seconds.
There is also a third configuration parameter in MicroRaft: leader heartbeat
period. It is the period for a leader Raft node to send heartbeats to its
followers in order to denote its liveliness. By default, a leader Raft node runs
a task
every 2 seconds. This task sends a heartbeat to each follower which did not
receive an
AppendEntriesRequest
in the last 2 seconds.
Dealing with disruptive followers
Pre-voting and leader stickiness exist to stop noisy followers from creating avoidable leader churn. This is a liveness story as much as a correctness one.
Raft's term and leader election logics can create some flakiness in some network failure cases. Consider a scenario where a follower Raft node disconnects from the rest of the Raft group, as Figure 1 shows. When the leader heartbeat timeout elapses, the follower moves to the next term and triggers leader election. Since it is not able to communicate with the other Raft nodes, after the leader election timeout elapses, it moves to the next term again and triggers another round of leader election. When it connects back to the rest of the Raft group, it causes the other Raft nodes, including the healthy leader, to move to its own term. The leader also steps down to the follower role while moving to the new term, and probably becomes the leader again in the next leader election round. Long story short, a temporarily-disconnected follower may hurt availability of the Raft group by causing unnecessary leader elections. Section 4.2.3 of the Raft dissertation describes a membership change scenario that could lead to the same problem.
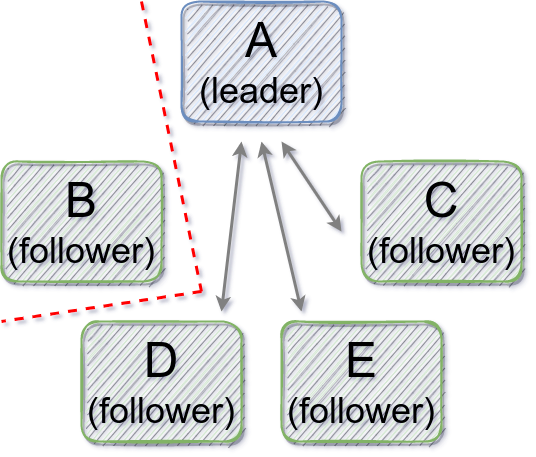
Figure 1
The Raft dissertation sketches out a solution to this problem, and Henrik Ingo
details the solution in his
Four modifications of the Raft consensus algorithm
work. The
idea is to add a pre-voting step before triggering leader election. MicroRaft
implements this. When the leader heartbeat timeout elapses, a follower Raft node
sends
PreVoteRequest
to other Raft nodes for the next term
without actually incrementing its local term. Other Raft nodes respond as if it
was an actual RequestVote RPC. They grant a non-binding pre-vote only if the
requesting follower's term is greater than or equal to their local term and the
requesting follower's log is sufficiently up-to-date. If the disconnected Raft
node collects the majority pre-votes, it increments the term and triggers an
actual leader election round. Otherwise, it retries pre-voting for the same term
after the leader election timeout elapses. If we integrate this solution to the
failure scenario described above, the disruptive Raft node retries pre-voting
until it connects back to the other Raft nodes. Then, it rediscovers the healthy
Raft leader in the same term and cancels pre-voting.
Let's make a slight modification in our failure scenario. In Figure 2, our unlucky Raft node disconnects only from the leader and can still communicate with the other Raft nodes. If the leader does not append a new entry to the log, the disconnected follower can succeed pre-voting, trigger an actual leader election round on the next term, and become the new leader. So pre-voting does not help to prevent an unnecessary leader election in this case and we get an unavailability window.
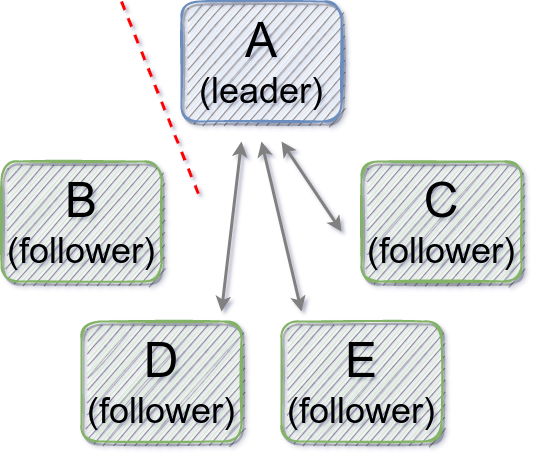
Figure 2
MicroRaft resolves this issue by relying on the heartbeat mechanism. Raft nodes ignore pre-vote requests if they think there is a live leader. A leader is considered alive if it has sent a heartbeat in the last leader heartbeat timeout duration. This solution is called leader stickiness and explained in both the Raft dissertation and Henrik Ingo's work.
Stepping down an overthrown leader
Check-quorum style demotion protects clients from talking to a leader that no longer has authority. That turns silent partial outage into explicit retryable failure.
Figure 3 demonstrates another case which is handled by MicroRaft to prevent partial unavailability in case of network problems. Suppose a leader Raft node is partitioned from the rest of its Raft group. Eventually, the other Raft nodes elect a new leader among themselves. However, since they are disconnected from the old leader, the old leader cannot observe the new term and leader information. This situation causes clients connected to the old leader to observe unavailability because the old leader neither fails nor commits their requests.
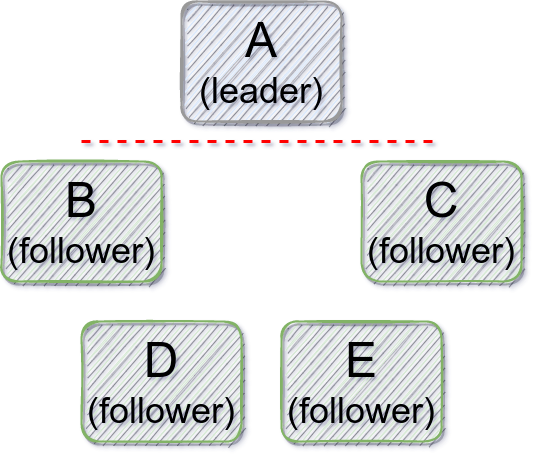
Figure 3
MicroRaft resolves this issue by relying on the heartbeat mechanism in a way
similar to the leader stickiness solution described above. The solution is also
described in Section 6.2 of the Raft dissertation. It is called Check Quorum.
A leader Raft node keeps track of AppendEntries RPC responses sent by
followers. It steps down if the leader heartbeat timeout elapses before it
receives AppendEntries RPC responses from the majority of the Raft group. It
also fails pending requests with
IndeterminateStateException
and new requests with
NotLeaderException
so that clients can retry their
requests on the other Raft nodes.
Sum up
MicroRaft's leader failure handling behavior is summarized below.
-
MicroRaft realizes leader election logic with 2 configuration parameters, leader heartbeat timeout and leader election timeout. Leader heartbeat timeout is the duration for a follower to detect failure of the current leader and trigger leader election. Leader election timeout is the duration candidates wait before giving up a leader election round and move to the next term for a new round. These 2 timeout values can be tuned separately to minimize unnecessary leader elections and delays caused by split votes.
-
Pre-voting and leader stickiness prevent unavailability when there are disruptive Raft nodes in a Raft group. MicroRaft ensures that a new leader election is started only if the majority of the Raft group thinks the current leader has failed.
-
With Check Quorum, if a leader Raft node does not notice that it has been taken down by another Raft node, it eventually steps down after the leader heartbeat timeout elapses, hence allows clients to retry their requests on the other Raft nodes and discover the new leader.
You can also check out Heidi Howard and Ittai Abraham's great post on the same topic.
Read next