Log replication in MicroRaft
A Java Raft replication deep dive on batching, follower acknowledgements, flush behavior, and commit progression under real write pressure.
At a glance
- How replication enters the Raft thread
- Why batching and flush amortization matter for throughput
- Why MicroRaft keeps one outstanding AppendEntries per follower
MicroRaft replicates a log entry as follows:
-
A client sends a request to the leader Raft node. This request contains an operation that is going to executed on the state machine once committed.
-
The leader Raft node creates a new log entry for this operation and appends it to the local Raft log.
-
The leader Raft node replicates the log entry to the followers.
-
The leader waits for acknowledgements from the followers. Once it learns that the log entry is appended by the majority of the Raft nodes, it commits the log entry by advancing the commit index.
-
The leader applies the log entry by passing the operation to the user-supplied state machine. Then, the value returned by the state machine is sent back to the client.
These steps must be executed serially for a single log entry. However, if we execute the whole process for only one log entry at a time, we end up with a sub-optimal performance. Hence, MicroRaft employs a number of techniques to commit log entries in a performant manner. In this article, we describe these techniques.
This post explains why replication throughput is not just “append and wait”. The important ideas are batching, amortized flush cost, and commit progression under load.
Handling client requests
Replication starts as a task-scheduling problem. This section shows where client calls enter the Raft thread and why the executor model matters for correctness.
MicroRaft's main abstraction is RaftNode. Clients talk to the leader Raft node
to replicate their operations. Raft node runs in a single-threaded manner and
executes the Raft consensus algorithm with the
Actor model. It uses another abstraction -with a default implementation- for this
purpose: RaftNodeExecutor. Raft node submits tasks to its RaftNodeExecutor to
handle API calls made by clients, RPC messages and responses sent by other Raft
nodes, and internal logic related to the execution of the Raft consensus
algorithm.
Raft nodes send RPC requests and responses to each other via Transport.
Transport is expected to realize networking outside of the Raft thread (i.e.,
RaftNodeExecutor's internal thread). Similarly, the communication between
clients and Raft nodes happens outside of the Raft thread. You can learn more
about MicroRaft's main abstractions and threading model here.
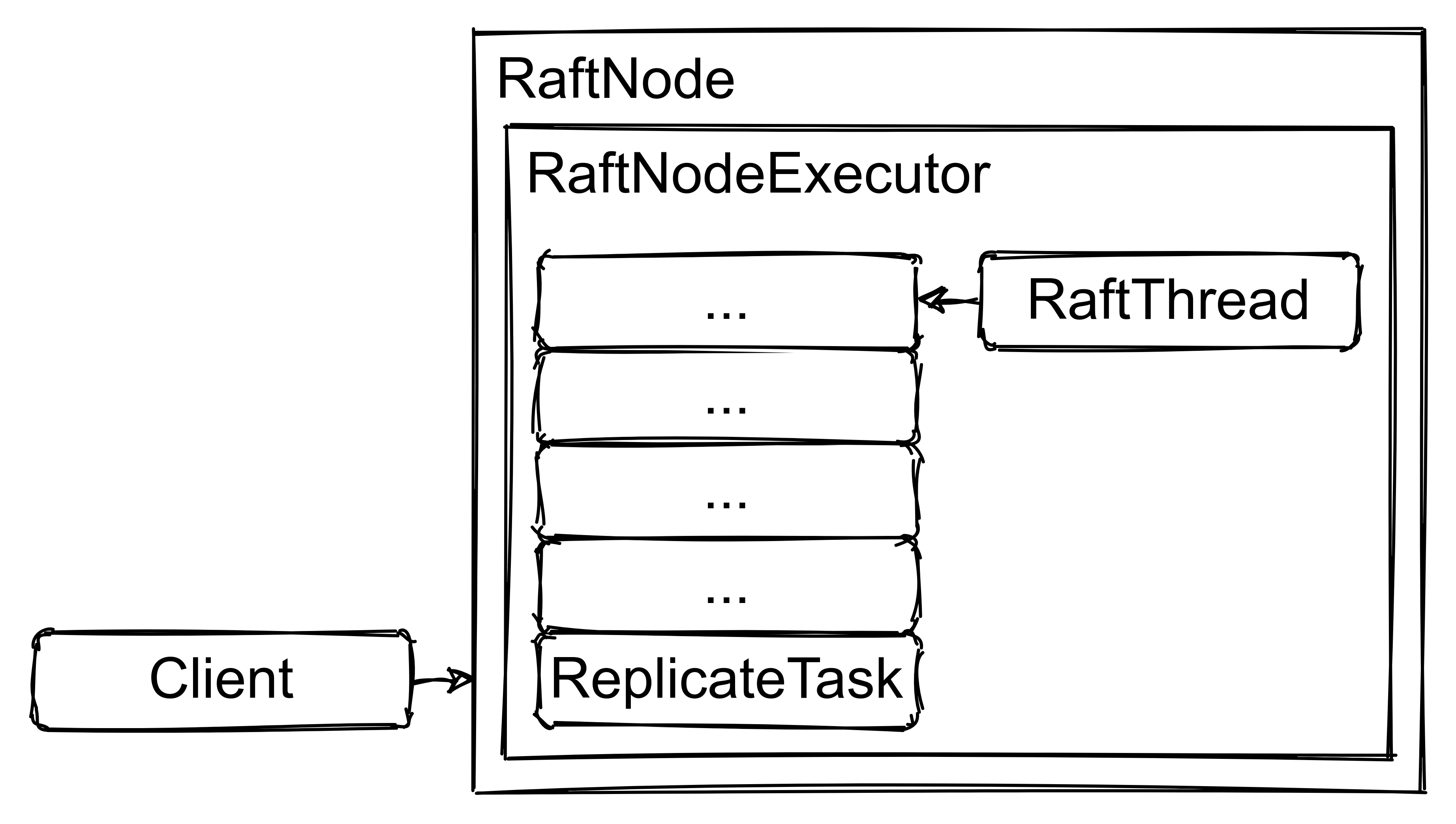
Figure 1 depicts the case when a client calls RaftNode.replicate() for an
operation. Upon this API call, Raft node creates an instance of ReplicateTask
and puts the task into the task queue of its RaftNodeExecutor.
RaftNodeExecutor's internal thread executes the tasks submitted to its task
queue.
When a ReplicateTask instance is executed by the leader Raft node, it creates a
new log entry for the client's operation, appends it the leader's log and sends
AppendEntriesRequests to the followers.
You can check the previous article to learn how MicroRaft implements the log.
For this article, it is enough for you to know that the log consists of 2
components: RaftLog and RaftStore. RaftLog keeps log entries in memory and
RaftStore writes them to disk.
Batching
Batching is the first major throughput lever. The leader adapts batch size to live request pressure instead of forcing one-entry-at-a-time replication.
Batching is a fundamental technique to improve performance. It is used to amortize processing costs of multiple requests. Raft offers a few opportunities to utilize batching. For instance, for each follower, the leader puts multiple consecutive log entries into an AppendEntriesRequest. This approach enables the leader to utilize the network better. It also enables followers to amortize the cost of disk writes. We elaborate this in the next section.
MicroRaft implements the batching policy described in the Section 10.2.2 of the Raft dissertation. After the leader Raft node sends an AppendEntriesRequest to a follower, it does not send another AppendEntriesRequest until the follower responds back. It can append new log entries into its local log in the meantime. Once the leader receives a response from a follower, it updates the follower's match index and sends all accumulated log entries in a new AppendEntriesRequest. This simple yet effective policy dynamically adapts batch sizes to the request rate.
MicroRaft limits the maximum number of log entries in AppendEntriesRequests via
RaftConfig.getAppendEntriesRequestBatchSize(). This is to prevent the leader
from saturating the network with large messages and causing the followers to
suspect its liveliness.
Followers acknowledge log entries in batches with this design, hence cause the leader to advance the commit index in batches.
Amortizing the cost of disk writes
Durability does not require a flush per entry. MicroRaft spreads expensive disk sync cost across multiple log entries on both leader and followers.
In a naive implementation of the log replication flow we described
in the intro, the leader writes each log entry to its own disk before
replicating it to the followers. So each log entry pays 2 serial disk-write
costs before it is committed: one in the leader Raft node when RaftLog passes
the log entry to RaftStore, and the second one in the follower Raft node before
it responds back to the leader to acknowledge that it has durably appended
the log entry. This behaviour prevents Raft nodes to amortize the cost of disk
writes, and also causes under-utilization of the Raft thread and higher commit
latencies.
RaftStore is designed to amortize the cost of disk writes. When RaftLog calls
RaftStore.persistLogEntry() for a log entry, the underlying implementation is
allowed to buffer the disk write instead of immediately flushing it. There is
also an API to flush all buffered writes to disk: RaftStore.flush(). When it
is called, the RaftStore implementation must guarantee the durability of
the buffered disk writes, i.e. fsync.
This design works well with the batching employed for log replication. When a
follower receives a batch of log entries via an AppendEntriesRequest, it
passes them to RaftStore.persistLogEntry() and then makes a final
RaftStore.flush() call to ensure their durability. By this way, followers
amortize the cost of disk writes.
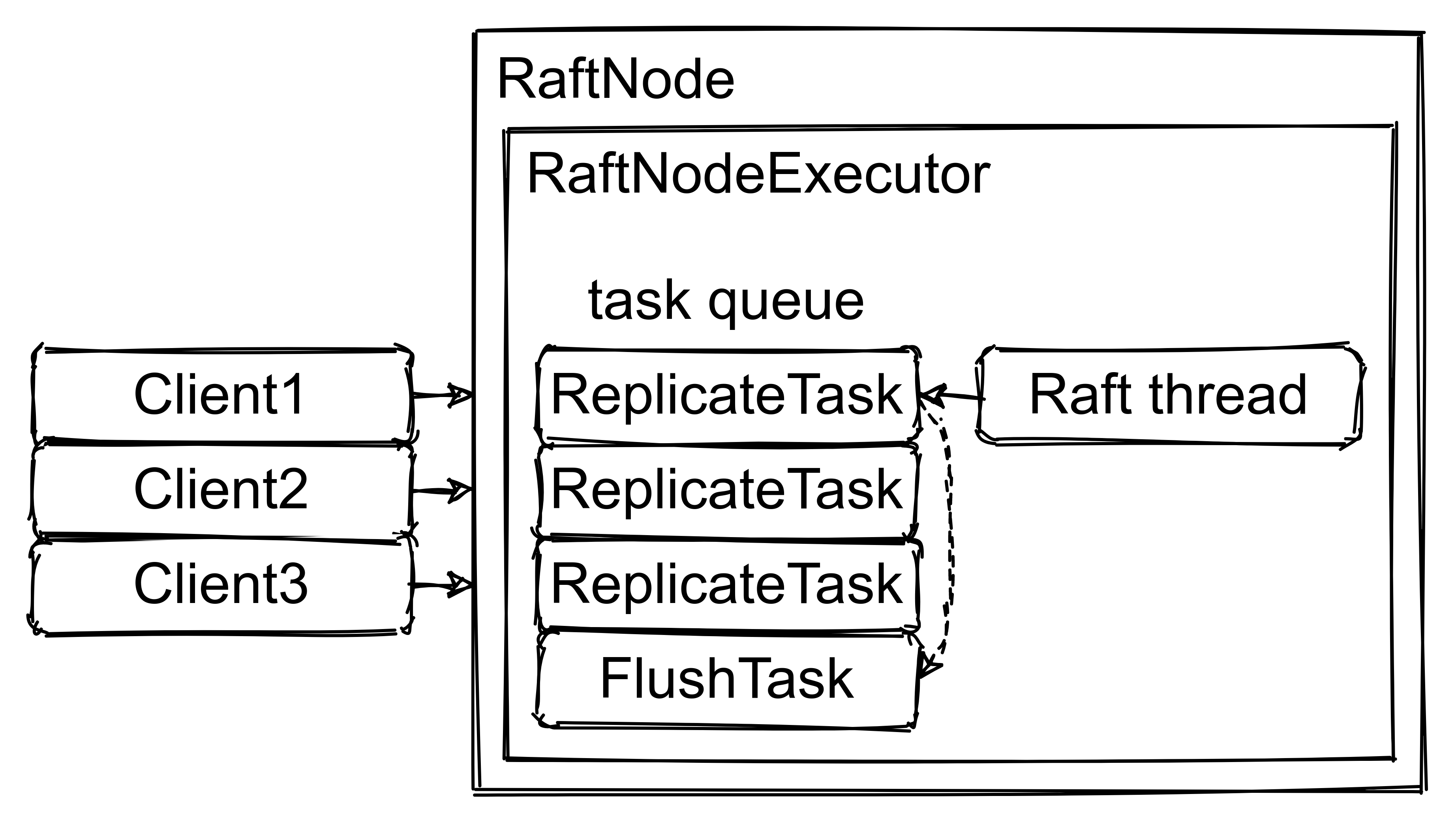
MicroRaft also employs the technique described in the Section 10.2.1 of the Raft
dissertation to amortize the cost of disk writes on the leader. When the
leader's Raft thread executes a ReplicateTask, it appends the new log entry to
the in-memory RaftLog, but does not immediately flush the disk write via
RaftStore. Instead, as Figure 2 demonstrates, it submits another task to perform
the flush: LeaderFlushTask. This task usually comes after multiple ReplicateTask
instances already submitted to the task queue by other clients. Therefore it
flushes all disk writes buffered until its execution.
This design enables the leader and followers to flush buffered disk writes in
parallel. In addition, since RaftStore.flush() typically involves costly
fsync calls on the kernel level, both the leader and followers amortize the
cost of fsync for multiple log entries.
Pipelining
Raft also supports pipelining in log replication. For instance, the leader can
send a new AppendEntriesRequest to a follower before it acknowledges the
previous one. Thanks to Raft's AppendEntries consistency check, followers can
also handle AppendEntriesRequests that are arriving out-of-order. However,
this approach complicates the management of match and next indices of
followers. Moreover, pipelining AppendEntriesRequests contradicts with
batching to some degree. Pipelining AppendEntriesRequests can reduce batch
sizes and increase the cost of networking and disk writes, and brings little
benefit if the cost of disk writes is significantly greater than networking.
Therefore, the overall improvement on performance highly relies on the effective
integration of batching and pipelining.
MicroRaft utilizes the concurrency between the leader and followers to improve
performance. For instance, the leader can append new log entries, advance the
commit index, or execute queries while followers are processing
AppendEntriesRequests. However, since the leader maintains a single outstanding
AppendEntries RPC for each follower, it does not pipeline
AppendEntriesRequests at the moment. We can implement this in future.
Wrap up
In Raft, the leader is responsible for managing the Raft group and replicating log entries. This strong leader-oriented approach simplifies several aspects of the solution to the consensus problem. However, it also causes the leader to become bottleneck very easily. Therefore it is very important to apply several techniques to replicate log entries in a performant manner. In this article, we investigated the techniques implemented in MicroRaft. Of course, we are not done yet. We still have a few more tricks in the tank to improve performance of log replication!
Read next